Atlas 1.1.0 Full GC 问题分析
问题背景
频繁接收到 Atlas 拨测告警,拨测程序是访问 atlas 查询 entity 的接口,一段时间都是 502 的返回,持续几分钟后恢复。查看 Atlas gc 日志,发现 Full GC 日志,并且持续时间和服务不可用时间吻合,基本确定就是由于 Full GC 导致。
GC LOG 分析
JVM 相关参数调整
查看 GC 日志发现,(concurrent mode failure)导致的 Full GC。
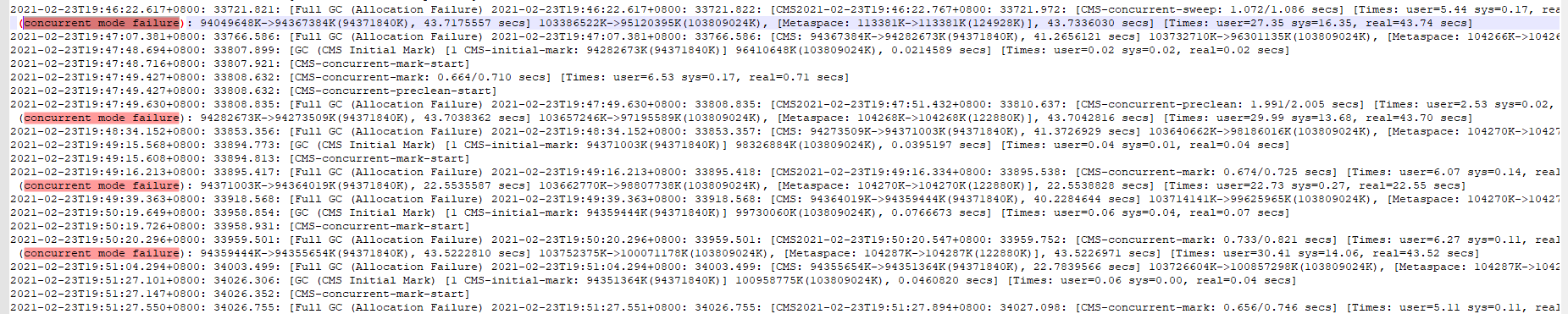
进行 JVM 参数调整,将 -XX:CMSInitiatingOccupancyFraction 设置为 50,即当老年代内存达到 50% 时,触发 CMS GC。
,参考:CMS之promotion failed&concurrent mode failure
完整参数:
1 | -XX:+CMSClassUnloadingEnabled -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+HeapDumpOnOutOfMemoryError -XX:CMSInitiatingOccupancyFraction=50 -XX:ParallelGCThreads=20 -XX:+CMSScavengeBeforeRemark -XX:MaxGCPauseMillis=400 -XX:HeapDumpPath=dumps/atlas_server.hprof -Xloggc:logs/gc-worker.log -verbose:gc -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=10m -XX:+PrintGCDetails -XX:+PrintGCDateStamps |
调整完参数后,执行以下命令,观察 GC 变化。
1 | jstat -gcutil PID 3000 |
发现 old Space 达到 50% 时,会触发一次 old GC,old Space 使用会下降,不过持续观察一段时间后,还是会出现 Full GC,调整内存还是会出现 Full GC 问题。
GC log 分析工具
可以使用 GC Log 分析工具,直观的看到 GC 变化。
GCViewer
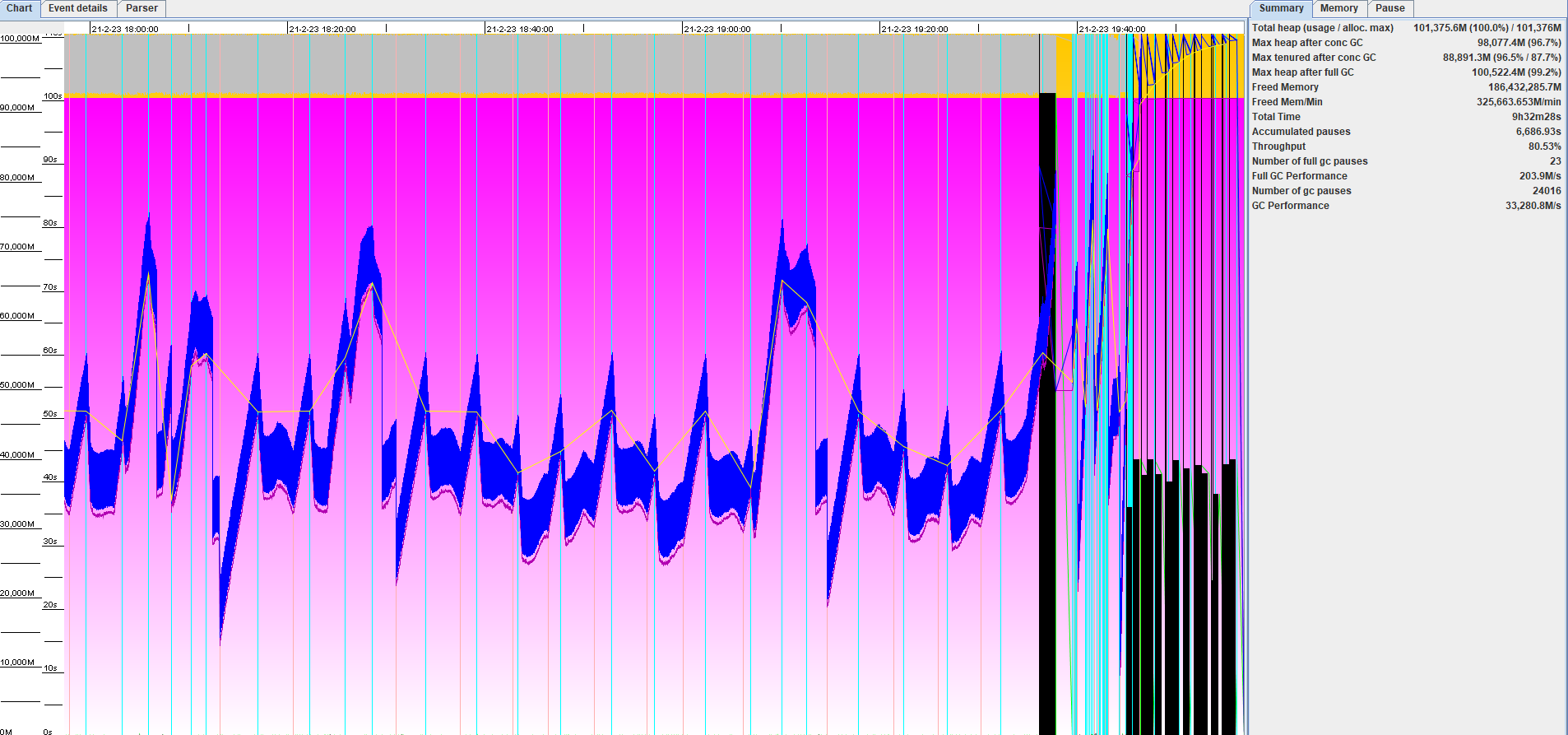
项目地址:https://github.com/chewiebug/GCViewer
使用说明:Results of log analysis
GCEasy
在线 GC log 分析,地址: https://blog.gceasy.io/
Dump 分析
经过一些 JVM 参数的调整和 GC Log 分析,还是无法避免 Full GC,感觉可能还是由于创建大量存活对象,顾对程序进行 Dump 分析。
生成 Dump 文件
生成 Dump 文件的方式有很多种,下面列举了几种方式。由于 jmap 生成 DUMP 文件时会导致服务挂起,对线上服务有影响,所以尝试使用 gcore 方式。不过将 gcore 导出的 core 文件转换成 bin 文件报错,没有具体研究。最终使用的 Arthas heapdump 命令(不太确定是否影响线上服务)。
Jmap 命令
1 | # 显示Java堆详细信息 |
Arthas heapdump 命令
具体参考:Arthas heapdump
Gcore
具体可参考:记一次Java服务频繁Full GC的排查过程
分析 Dump 文件
使用 jhat 分析 dump 文件。
1 | # dump.hprof 为 Dump 文件路径 |
分析完成后,访问 http://IP:7000 ,查看详情。点击 ‘Show heap histogram’ 可查看堆中对象统计信息。

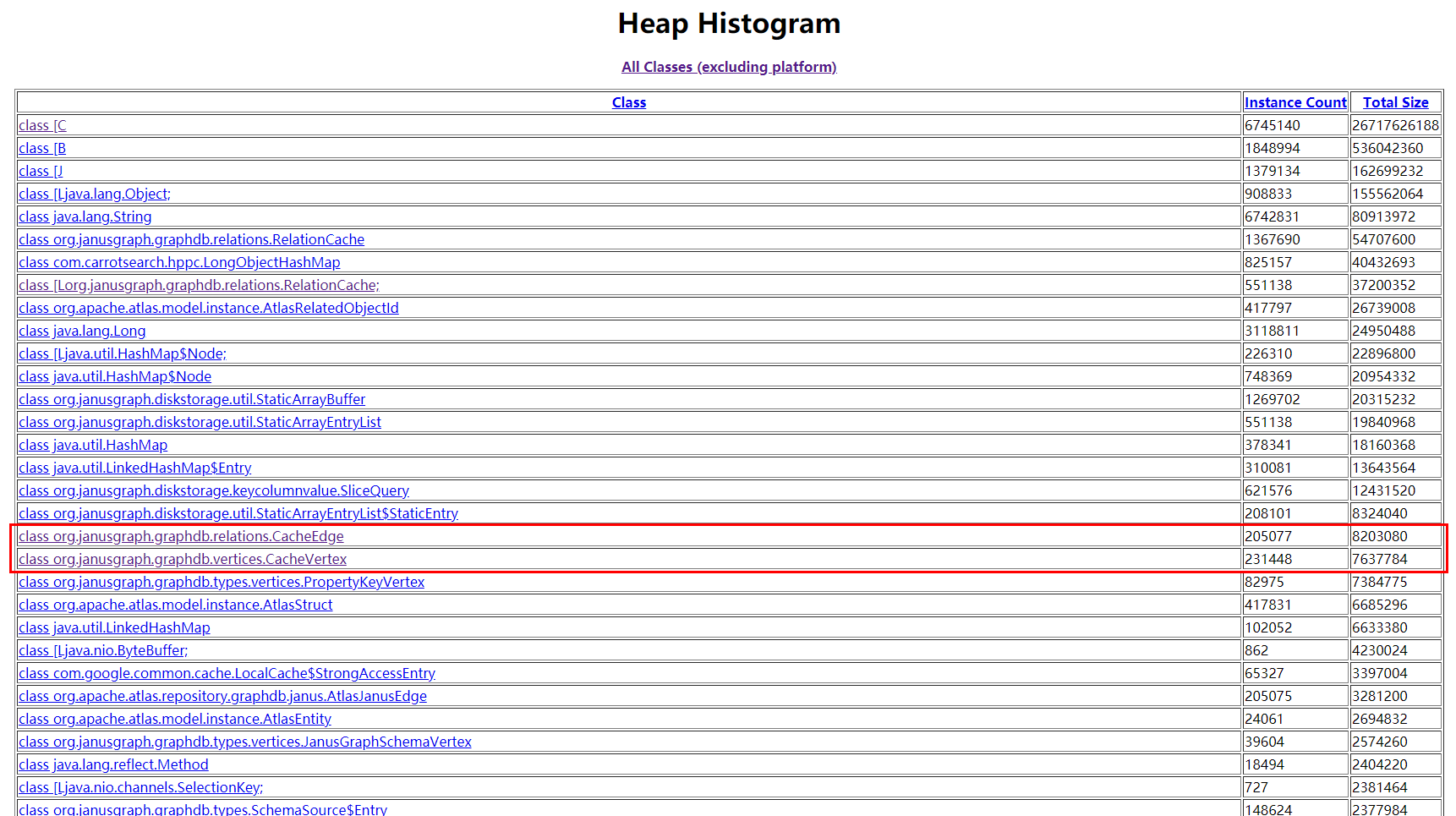
点击占用内存较高的对象,并抽样分析引用该对象的对象(References to this object 中的对象),关注到大多都指向了 CacheEdge 和 CacheVertex 两个类型的对象,这两个对象应该是 JanusGraph 中顶底和边。
查看 CacheVertex 的关联对象,发现主要来自 LocalCache 和 CacheEdge 两个类型对象。
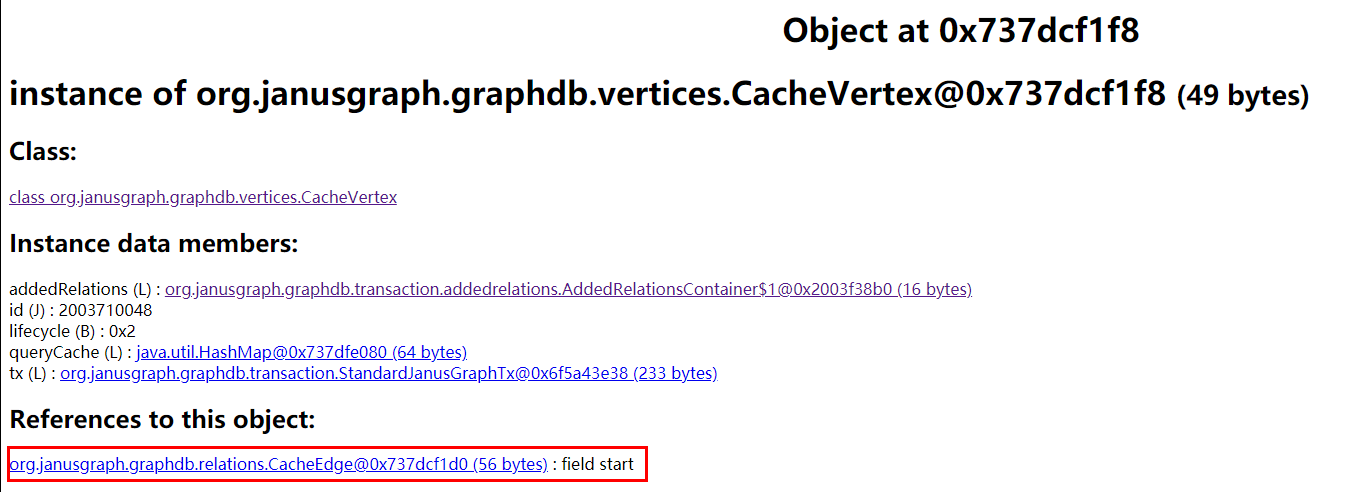
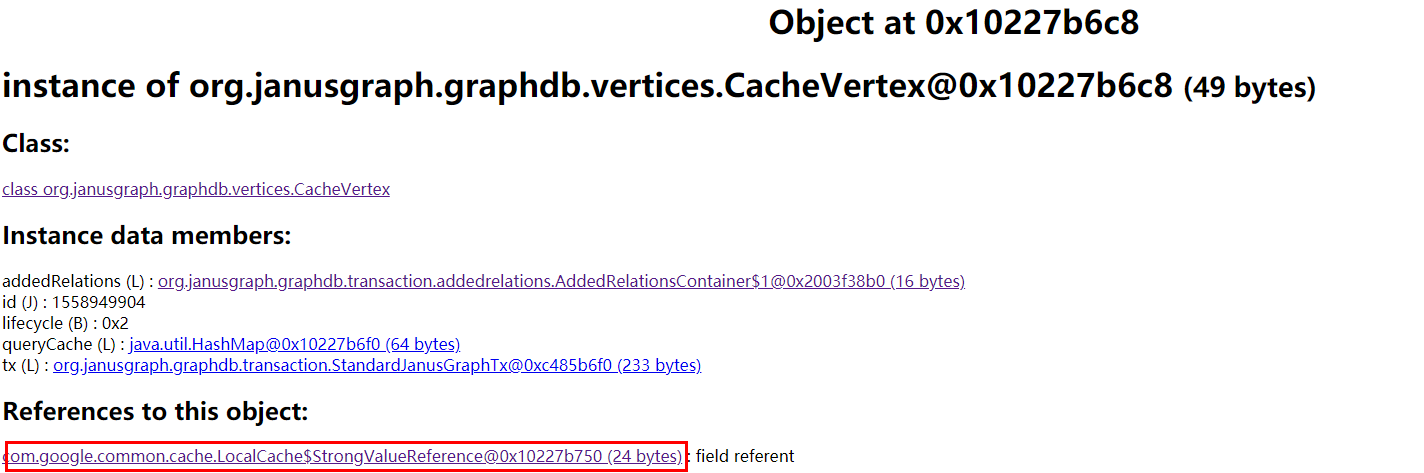
JanusGraph 缓存
分析 LocalCache 对象,来自 com.google.common.cache.LocalCache.LocalManualCache 对象,是 Guava 的缓存工具。从对象引用确定到与 JanusGraph 的两个地方的缓存有关:
1 | org.janusgraph.diskstorage.keycolumnvalue.cache.ExpirationKCVSCache#ExpirationKCVSCache |
ExpirationKCVSCache 用于 JanusGraph 全局的 KeyColumnValue 缓存,db-cache-size 参数表示缓存最大占用总堆内存的百分比(小于 1 时),或指定缓存大小(大于 1 时),默认为 0.3。
GuavaVertexCache 用于 Transaction 中的 Vertex 缓存。tx-cache-size 参数表示一次事务中最大缓存 Vertex 的大小,JanusGraph 中默认为 20000,Atlas 里面默认为 15000。
怀疑是否是缓存过大导致,顾对以下参数进行调整。
1 | atlas.graph.cache.db-cache-size=0.2 # |
查找元凶
对缓存进行调整后发现还是出现 Full GC 继续分析 Dump 文件。
CacheVertex 和 CacheEdge 对象相互引用,看到部分 CacheVertex 被大量 CacheEdge 引用。猜测是否由于一个定点有很多的边导致的。

使用 OQL 查询被引用对象超过 1000 的 CacheVertex,具体语法参考:Object Query Language。
1 | select { name:v, id: v.id, count: count(referrers(v))} from org.janusgraph.graphdb.vertices.CacheVertex v where count(referrers(v)) > 1000 |
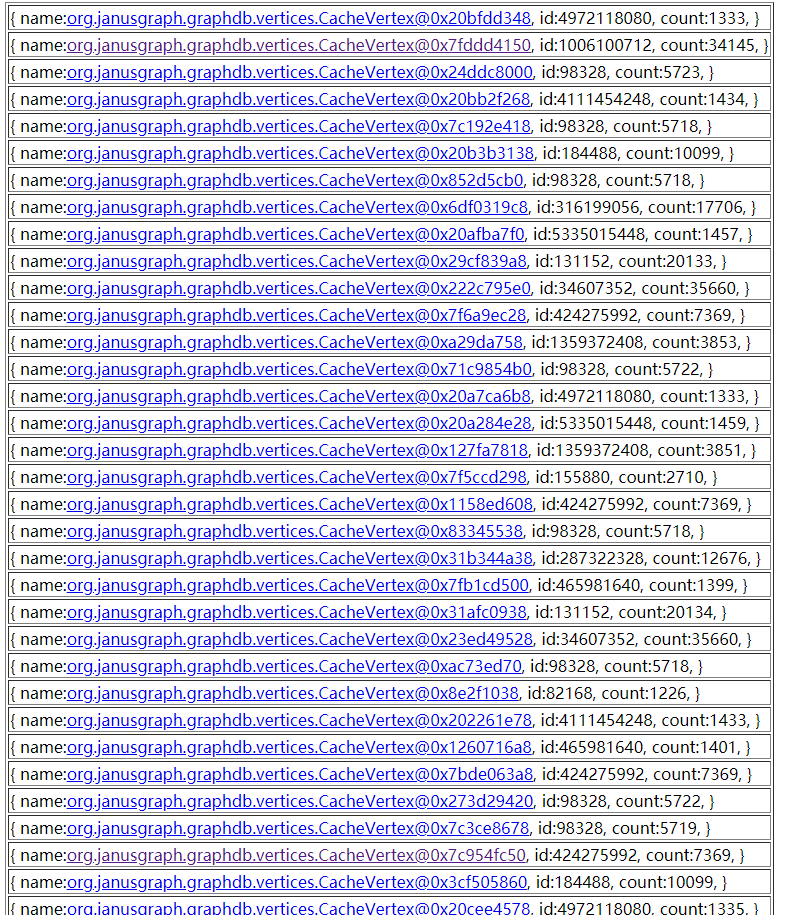
可以看到有个定点甚至有几万的边,使用 Gremlin 查询这些 Vertex,发现主要是下面两种情况,这里操作参考之前文章:Gremlin Server/Console 适配 Atlas JanusGraph。
1 | gremlin> g.V(1006100712).properties("__typeName") |
可以看到 hive_db 的情况,应该是会查询出 hive_db 的所有 hive_table,正常的操作不应该查询出所有的关联对象,再对程序进行 jstack 分析。
解决问题
再对程序进行 jstack 分析,这里需要注意需要在程序正常运行是进行 jstack,不要在 Full GC 发生时进行 jstack。
通过查看 jstack log 注意到的 org.apache.atlas.repository.store.graph.v2.EntityGraphRetriever#mapRelationshipAttributes 方法,这个方法会遍历 relationship 的对象,会导致大量对象的创建。
1 | "NotificationHookConsumer thread-40" #522 prio=5 os_prio=0 tid=0x00007f897794d000 nid=0x98e5 runnable [0x00007f69c4ecd000] |
根据上面两个线程栈信息,定位在了下面两个方法,具体的修改参考 Atlas 2.1.0 代码进行修改,这里主要是去掉不必要的 Relationship 查询。
1 | org.apache.atlas.repository.store.graph.v2.AtlasEntityChangeNotifier#toAtlasEntities |
修改后问题解决,消费性能大幅度提高,后续计划升级至 Atlas 2.1.0。