问题背景
数据同步任务是为了做跨集群的 Hive 数据同步,通过 Spark 读取源集群 Hive 数据源,再写入目标集群 Table Location 的 HDFS 路径。
用户批量执行 Spark 同步任务时(写同一个表的不同分区,大多是为了补历史数据的任务),部分分区数据丢失。
问题定位
通过 Spark sql 对比,源集群和目标集群的数据,发现部分分区确实存在数据丢失。
查询目标集群丢失数据分区的 HDFS 目录,发现确实缺少部分 parquet 文件(parquet 文件缺少部分序列)。
查看 NameNode 日志,发现 Parquet 文件是先写到 ${TableLocation}/_temporary 目录中,在 rename 到目标目录。
继续在 NameNode 日志中查找丢失目录的 temp 文件,发现只有 Create 操作,没有 Delete 操作,不过发现了多个客户端在写同一个 _temporary 目录,并有删除操作。
临时路径如何确定
Spark 写文件的入口类为:org.apache.spark.sql.execution.datasources.FileFormatWriter
org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter 类是用来定义 MapReduce 任务 Job 的输出,包括 Job Task 输出路径的初始化、清理等工作。其中定义了temp 目录为 ${RealOutput}/_temporary 。
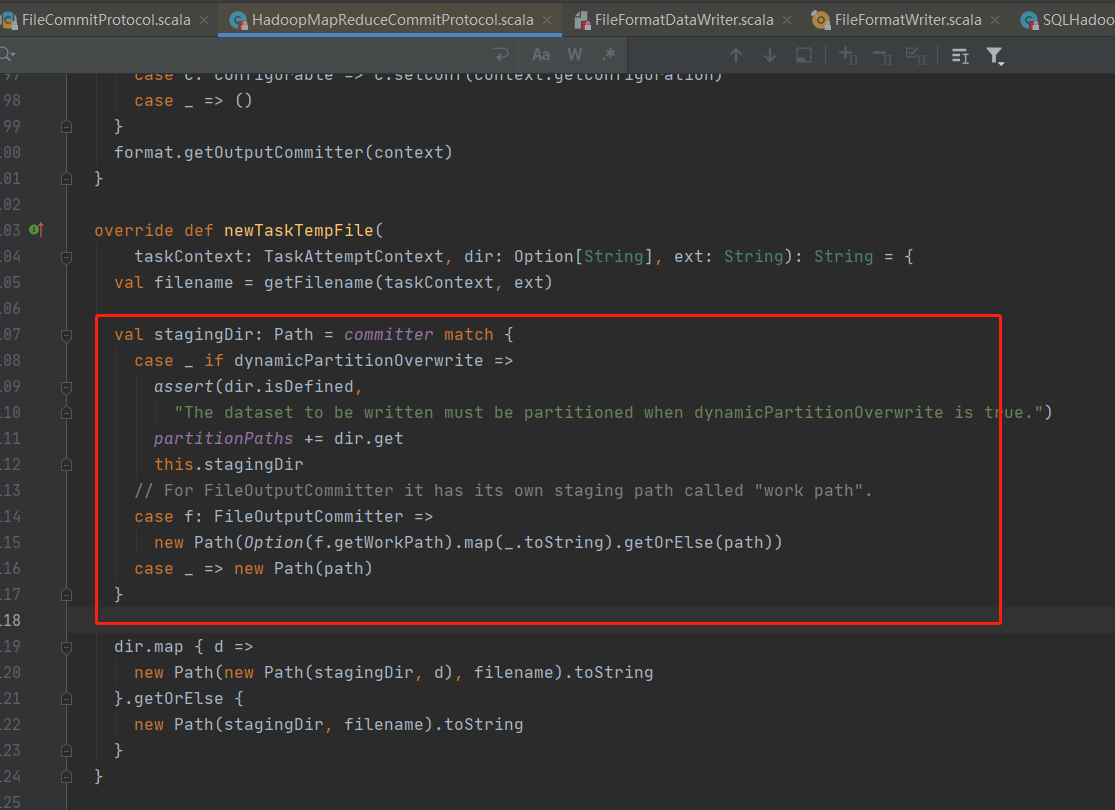
Spark 任务为 FileOutputCommitter 做了一层代理 org.apache.spark.internal.io.FileCommitProtocol,部分场景使用到了 stagingDir 作为 output 路径。
org.apache.spark.internal.io.HadoopMapReduceCommitProtocol#newTaskTempFile,当 dynamicPartitionOverwrite 为 true 时,临时路径在 spark stagingDir 中则每个任务不会重复。
Spark 通过 Hive 写入是如何保证的
Spark 中保存 Hive 表数据,实际上写入的路径改成了 hive staging 的路径,具体代码:org.apache.spark.sql.hive.execution.SaveAsHiveFile#getExternalTmpPath 中,然后进行 load partition。这个相当于直接将写入的 basePath 路径改变了,所以不会存在冲突。
解决方法
方法一(没有采用): 将 saveMode 设置为 Overwrite,partitionOverwriteMode 设置为 dynamic,这样写入的temp 目录就在 stagingDir 中,不过 overwrite 模式写入会先清空目标分区,所以没有采用。
1 | resultDF.write.partitionBy(partitionColumn: _*) |
方法二:定义 Temp 目录为 ${TableLocation}/${JobId},确保写入路径不重复,在将 Temp 目录 merge 到 target 路径中。
1 | resultDF.write.partitionBy(partitionColumn: _*).mode(writeMode) |
其他
写入对象存储的性能调优,也与 FileOutputCommitter 这块有关。参考: 存算分离下写性能提升10倍以上,EMR Spark引擎是如何做到的?