一、背景
Spark 程序在运行时会会在 Driver 端产生一些事件并保存在 EventLog 中,Spark History Server 通过读取并 Replay 这些 Event 可以渲染出 Spark UI 页面,Spark UI 页面中包括了我们排查问题所需的大部分指标和统计信息。
所以我们可以通过在 Spark Event Log 中提取一些关键信息,用于发现 Spark 的一些问题并进行优化,同时也可以对历史运行的任务进行统计,为一些优化效果提供数据支撑。
二、Spark SQL 读取 Event Log
Spark 中 Event log 是通过 JSON 格式进行序列化写入文件中,所以我们可以直接使用 Spark JOSN File Datasource 方式直接读取 Event Log。
1、直接读取Event Log
1 | select * from `json`.`hdfs://rbf-bdxs-g1/system/spark/tmp/spark/logs/application_1663317691313_4806906_1` limit 10; |
2、为 EventLog 文件创建一下视图
参考:https://spark.apache.org/docs/latest/sql-ref-syntax-ddl-create-table-datasource.html
1 | CREATE OR REPLACE TEMPORARY VIEW `application_1663317691313_4806906` ( |
三、Hive SQL 读取 EventLog
Hive 中可以通过配置 TEXTFILE ‘org.apache.hadoop.hive.serde2.JsonSerDe’ 序列化方式的表也可以直接读取 JSON 文件。
1 | CREATE EXTERNAL TABLE IF NOT EXISTS `sample`.`spark_event_log`( |
四、分区读取 Event Log
通过上面一些尝试,我们可以确定能够通过 Spark SQL、Hive SQL 来读取 Event Log 文件。
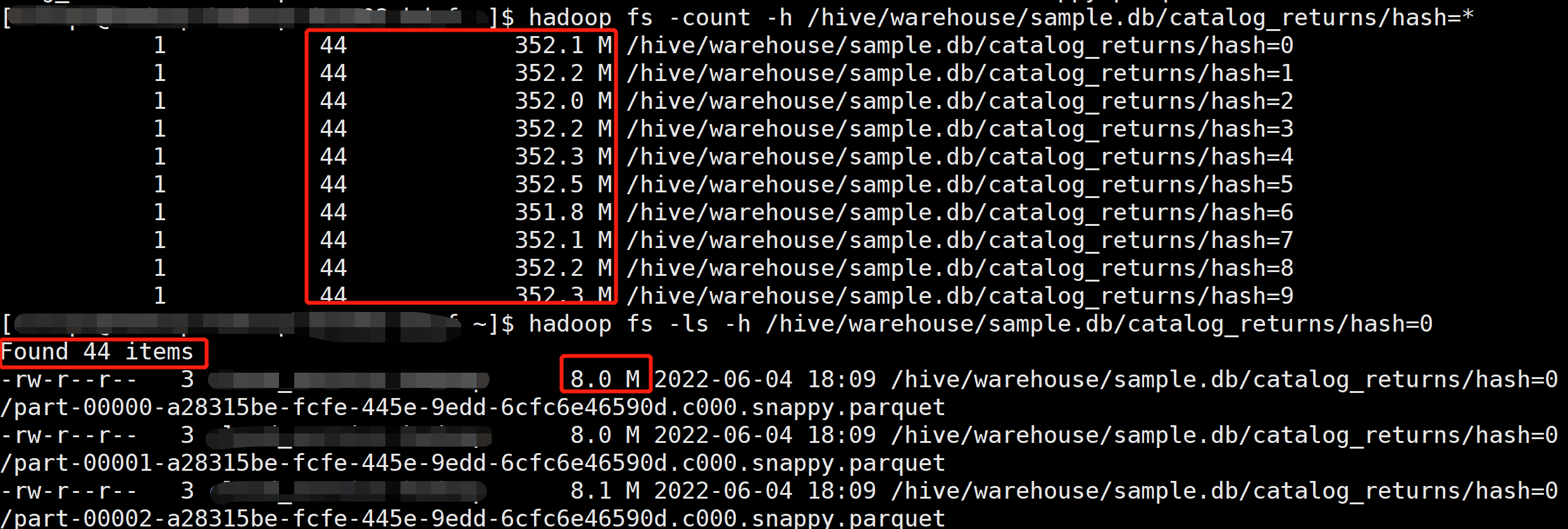
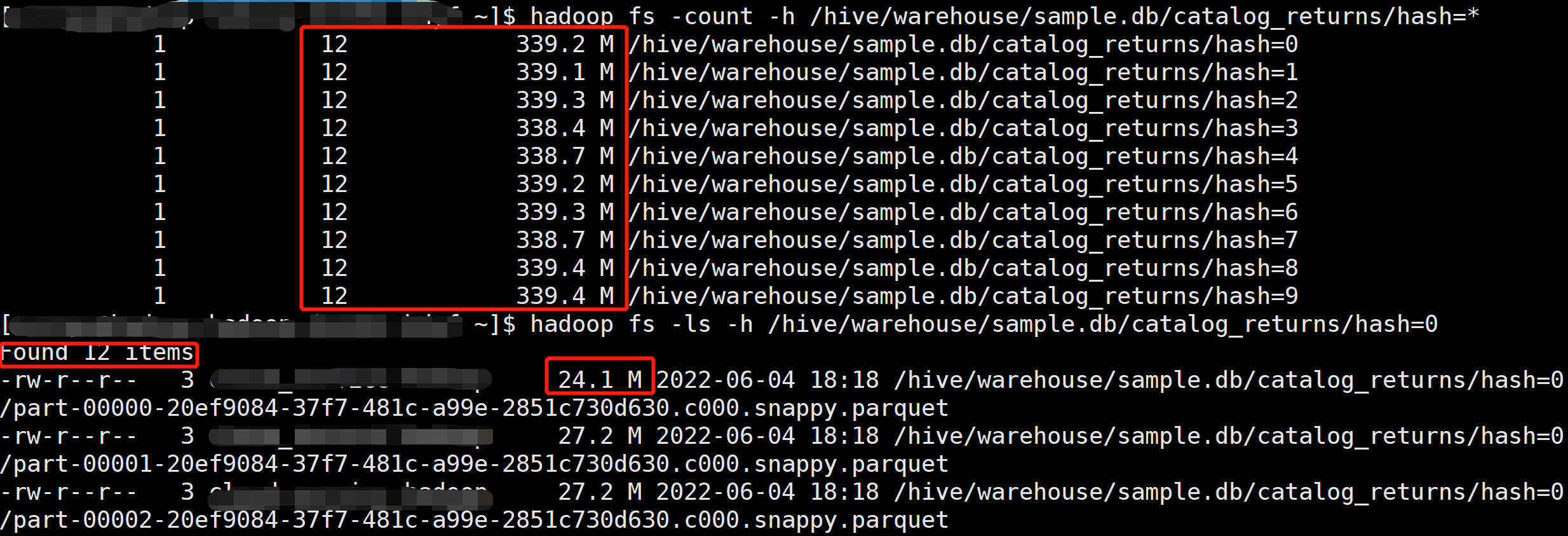
不过由于所有的 Application 都写在同一个 Event Log 路径中,我们很难过滤部分 Application 的 EventLog,所以我们需要为 Event Log 添加一些分区,使得我们可以按照分区来过滤一些数据,不用每次都全量读取。
1、Load Data 方式加载到 Hive 表中
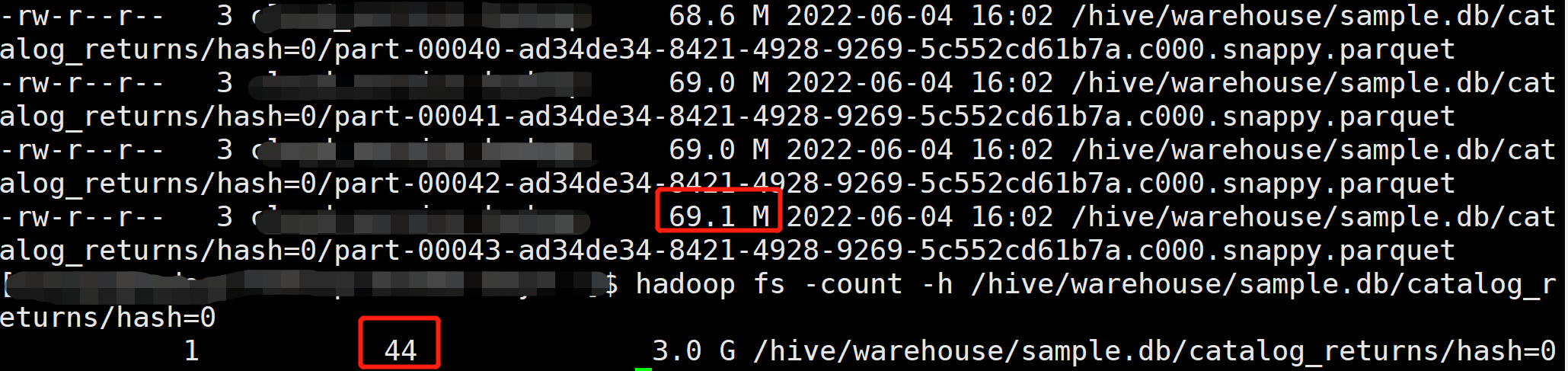
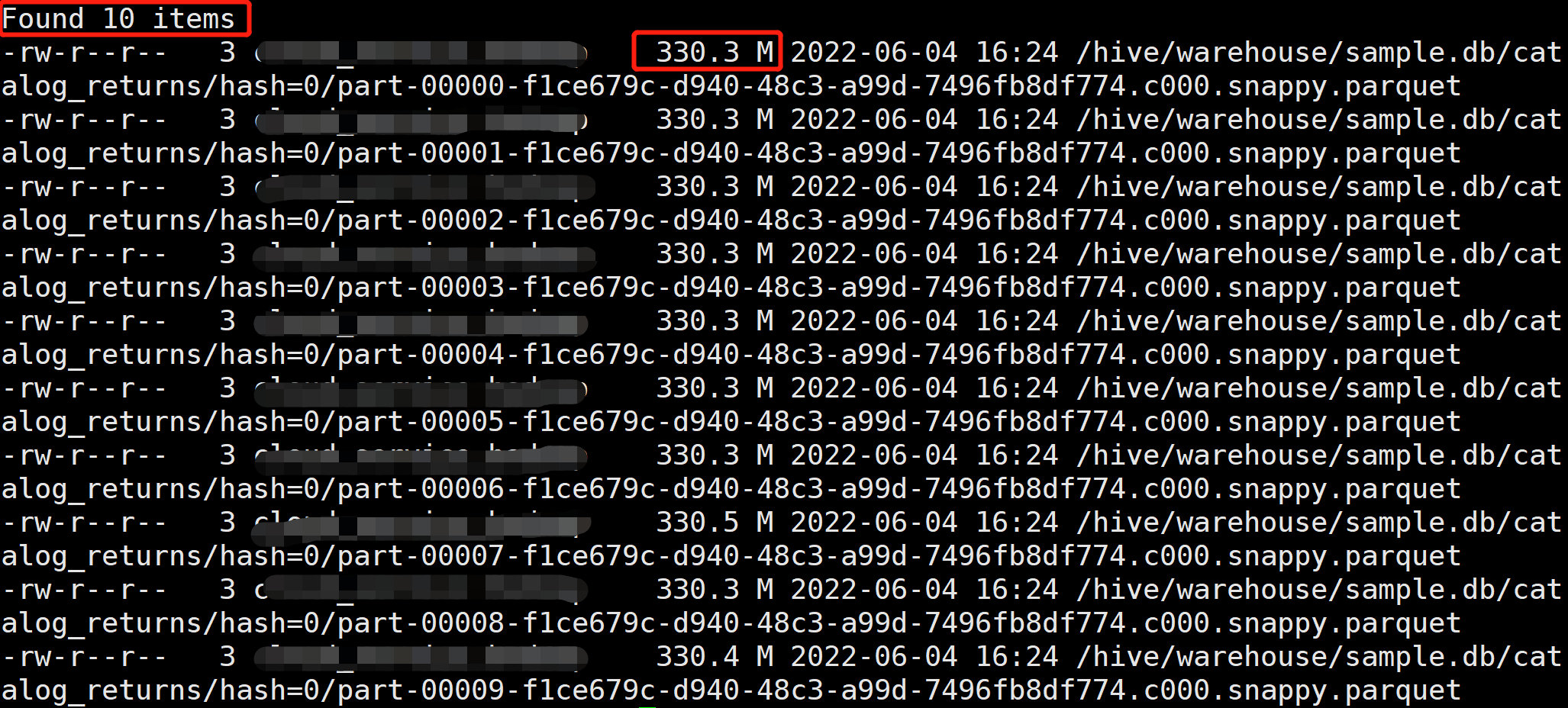
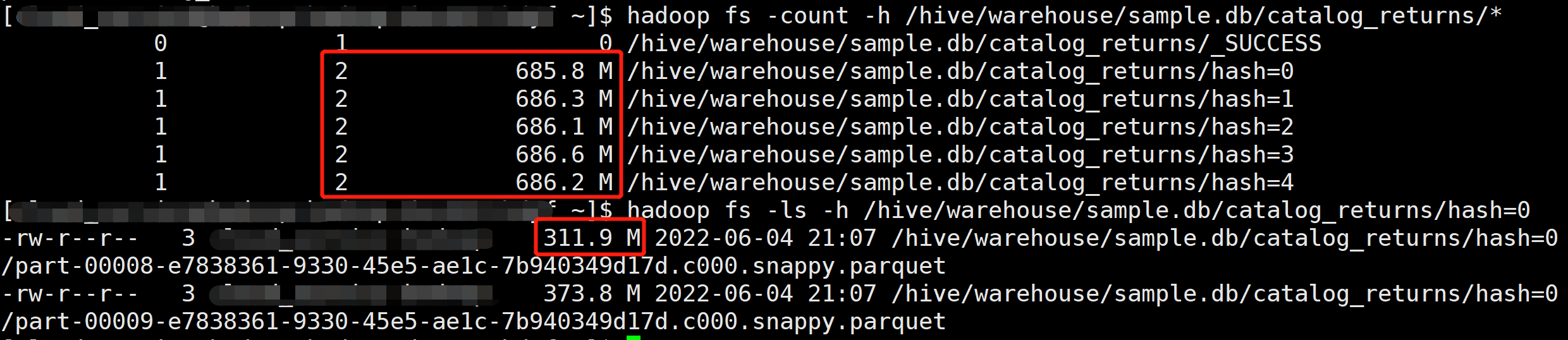
在 Hive 中创建一个分区表,然后通过 Load Data 方法将 Event Log 文件加载到对应的分区中,不过测试下来发现 Load data 命令会删除源文件。
我们也可以直接将文件拷贝到表的分区目录中,再为表添加对应的分区,不过这种方式相当于对源文件多个一个备份。
1 | CREATE EXTERNAL TABLE IF NOT EXISTS `sample`.`spark_event_log_002`( |
2、Spark EventLog Connector
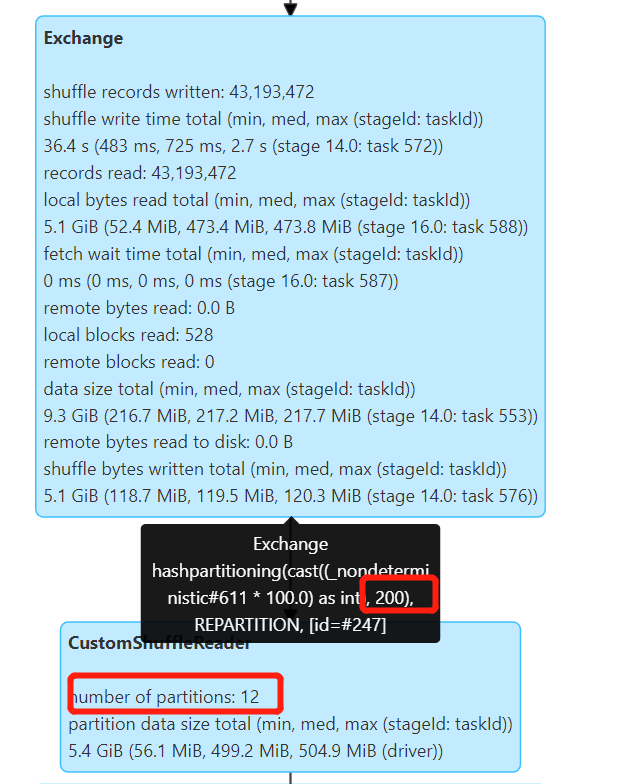
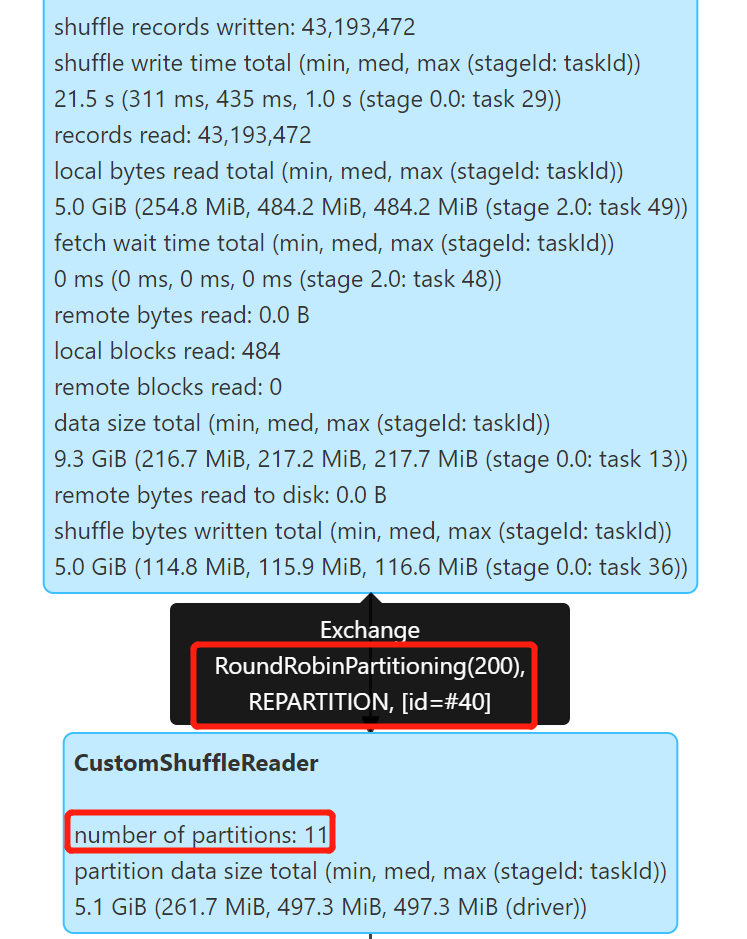
为了让 Spark SQL 直接读取 Event Log 文件,并且对 Event Log 添加分区信息,我通过 DataSourceV2 的方式实现一个 EventLog Catalog 和 Table,复用了 JsonTable 的大部分逻辑,并重写 JsonScan 的 partitions 逻辑。
实现了直接通过 Catalog 读取 Event Log 并支持 dt、hour、app_id 三级分区。
代码:https://github.com/wForget/spark-connector-eventlog
具体使用:https://github.com/wForget/spark-connector-eventlog/blob/main/README.md
配置 EventLog Catalog:
1 | spark.sql.catalog.eventlog=cn.wangz.spark.connector.eventlog.EventLogCatalog |
访问 Event Log:
1 | // 可通过设置 maxPartitionBytes,控制每个 task 处理的数据量 |